Unsupervised Thoughts A blog on machine learning
Adding Text (Really) inside Pictures and Videos

In the image above and the video below, the left character partially hides the text. In this post, I show how to automatically create such effect with a pretrained deep learning model and traditional computer vision techniques.
I focus here on the general approach and you can see the implementation details (and create your own videos!) with the attached notebook. You can also edit pictures through a user-friendly web app.
Adding Text to a Single Picture
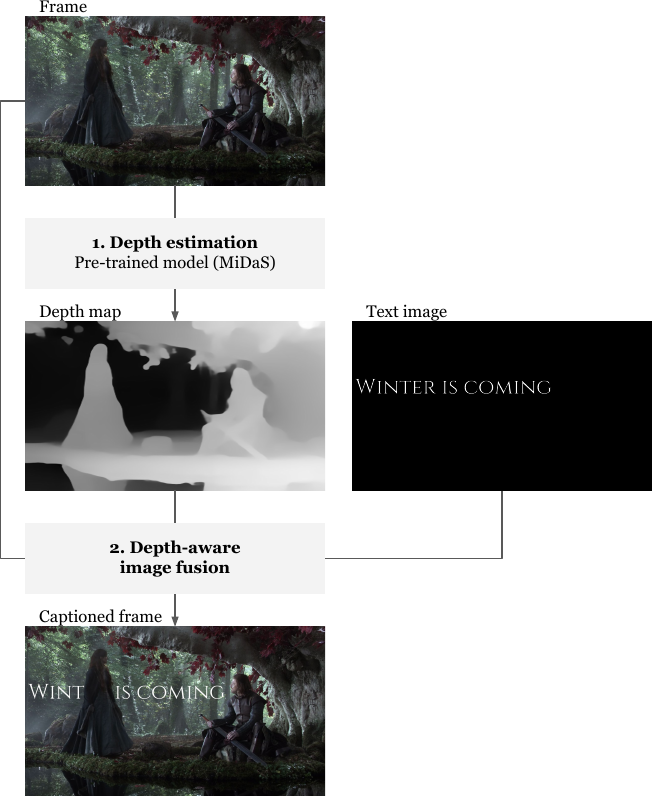
As illustrated in the following diagram, adding text to a single picture is straigthforward:
-
Depth estimation: we get a depth map of the picture with MiDaS (Ranftl et al., 2020)(Ranftl et al., 2021), a deep learning model trained specifically for this task.
-
Depth-aware image fusion: we prepare an image with the desired text over a transparent background and we specify a depth threshold. We then merge it with the initial image on the basis of the depth map: for each pixel, if its depth is below the threshold, we keep the color of the initial image and if not, we replace it with the color of the text image.
Aligning two Frames
With videos, the result is much more convincing if the added text seems static even though the camera moves. If we have already chosen the position of text for a reference frame and want to determine the position for another frame, we need to estimate the camera movements between the two frames. We’ll then be able to compensate them to create the illusion of a static text.
This is done in 3 steps:
-
Keypoints detection and description: we use ORB (Rublee et al., 2011) and BEBLID (Suárez et al., 2020) to detect keypoints in both frames and obtain their descriptions. Keypoints are pixels whose neighborhood is distinctive (e.g. a pixel located at a corner) and the descriptions are binary vector representations of these neighborhoods’ visual appearance. In the OpenCV implementation of ORB, it’s possible to detect keypoints only in a region of an image so we take advantage of the depth maps we already computed to look for keypoints only in the background. We can indeed assume that these keypoints would better reflect the camera movements.
-
Keypoints matching: for each keypoint of the reference frame, we search for keypoints with a similar description in the other frame and we do so naively by testing all potential pairs. This yields a list of matched keypoints.
-
Affine transformation estimation: we look for the affine function that best transforms the keypoints of the reference frame into the ones of the other frame. For this, we could use a simple linear regression. However, there can be false positives among the matched keypoints or the changes of these keypoints from one frame to another may not be caused only by the camera motion. This is why we use RANSAC (Fischler & Bolles, 1981), an iterative curve fitting method robust to outliers.

Adding Text to a Video
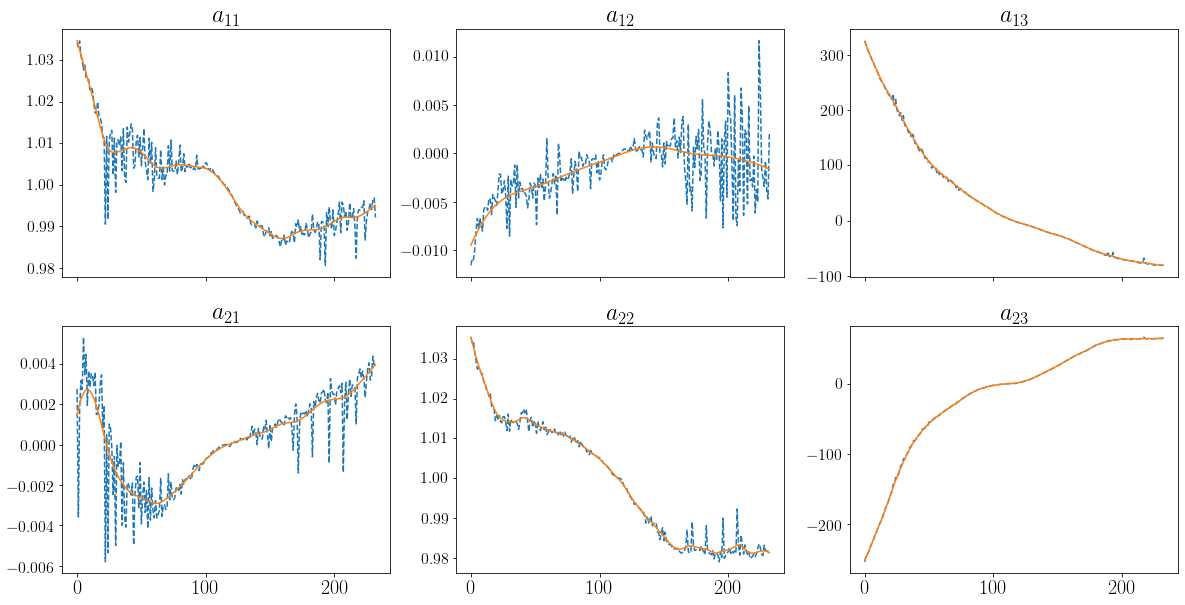
We’re almost there! For each frame of a video, we now know how to determine the affine function best aligning this frame with a reference frame and we could use this affine function to transform the text image before merging it with the frame. However, the estimation errors of the affine function would then make the text appear jittery. This is why we use a nonparametric kernel regression to smoothen all parameters of the affine function over time.
Conclusion
I find it satisfying to see how traditional computer vision methods and a deep learning model can be jointly used to produce convincing results. It’s also pleasantly straightforward to combine these techniques with powerful Python libraries like OpenCV and transformers. I hope you’ve enjoyed this blog post. Let me know if you use the notebook to create cool videos!
This project was inspired by the official video of Jenny of Oldstones by Florence + the Machine and built with OpenCV, transformers, the MiDaS model and Google Colab.
References
- Ranftl, R., Lasinger, K., Hafner, D., Schindler, K., & Koltun, V. (2020). Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI).
- Ranftl, R., Bochkovskiy, A., & Koltun, V. (2021). Vision Transformers for Dense Prediction. ArXiv Preprint.
- Rublee, E., Rabaud, V., Konolige, K., & Bradski, G. (2011). ORB: An efficient alternative to SIFT or SURF. 2011 International Conference on Computer Vision, 2564–2571. https://doi.org/10.1109/ICCV.2011.6126544
- Suárez, I., Sfeir, G., Buenaposada, J. M., & Baumela, L. (2020). BEBLID: Boosted Efficient Binary Local Image Descriptor. Pattern Recognition Letters. https://doi.org/https://doi.org/10.1016/j.patrec.2020.04.005
- Fischler, M. A., & Bolles, R. C. (1981). Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM, 24(6), 381–395. https://doi.org/10.1145/358669.358692