Unsupervised Thoughts A blog on machine learning
An Optimal Lossy Variant of Speculative Decoding

Speculative decoding (Leviathan et al., 2023; Chen et al., 2023) is an elegant decoding strategy for autoregressive language models. It accelerates text generation while preserving the target distribution. In this blog post, I introduce mentored decoding, a novel, provably optimal, lossy variant of speculative decoding. It further increases the decoding speed at the cost of a bounded deviation from the target distribution.
I will first summarize the principle of speculative decoding. I will then present mentored decoding and explain in what sense it is optimal. I will finally comment some initial experimental results and suggest further explorations.
- Speculative Decoding
- Mentored Decoding
- Solving the Optimization Problem
- First Experimental Results
- Conclusion and Further Work
- References
Speculative Decoding
Let me first tell you a story which will hopefully help you understand speculative decoding and, in the subsequent section, mentored decoding. Alice is a talented writer who can only speak or write very slowly. Fortunately, her longtime assistant, Bob, has been helping her write books in the following manner:
- Given the current manuscript and his knowledge of Alice’s works, Bob imagines what the next few words can be and writes down these candidate words;
- Alice points to the last candidate word she could indeed have written herself;
- Alice writes the next word;
- All the words selected at Steps 2 and 3 are added to the manuscript, the other candidate words are discarded and we go back to Step 1.
This can save a lot of time if Bob guesses Alice’s next words reasonably well and writes much faster than her. Moreover, the final manuscript would be indistinguishable from a book written by Alice alone.
As it is probably clear for you now, Alice and Bob actually correspond to autoregressive language models. Similarly to blockwise parallel decoding (Stern et al., 2018) or assisted generation (Joao Gante, 2023), speculative decoding combines a large target model and a small draft model (typically ten times smaller than the target model).
More precisely, assuming that:
- the vocabulary of the tokenizer is \(V\);
- The next token probability distribution of the draft model is \(p(.\mid.)\);
- The next token probability distribution of the target model is \(q(.\mid.)\);
- The initial prompt and the text generated so far are \(x_1, ..., x_n\);
… speculative decoding would select the next tokens as follows:
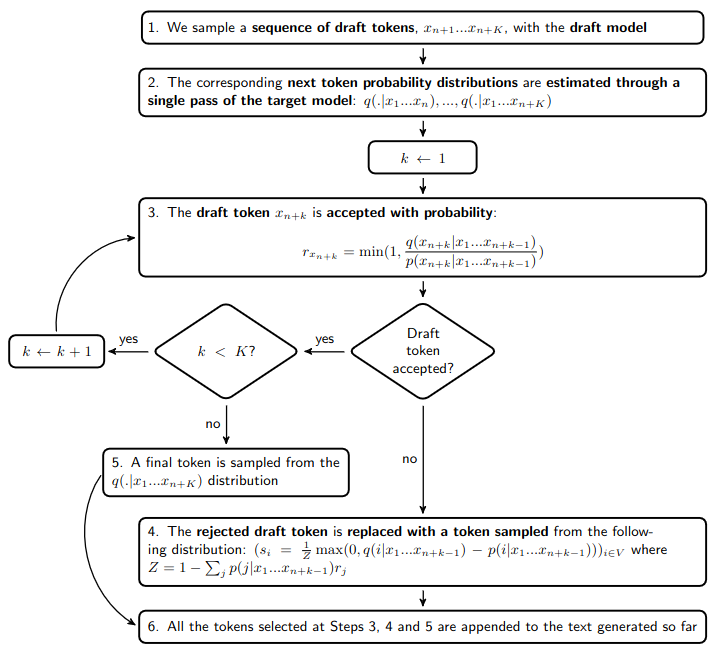
Speculative decoding typically doubles the decoding rate. This speedup comes from the fact that estimating the next token probability distributions with the target model at Step 2 takes approximately as much time as generating one token with this target model. Moreover, the formulas for the acceptance probability \(r_{x_{n+k}}\) at Step 3 and the replacement token probability distribution \((s_i)_{i \in V}\) at Step 4 are such that the generated text provably follows the target distribution.
Under this condition, these formulas actually maximize the probability to accept the draft token: \(\sum_{i \in V} p_i r_i\). This means that we need to deviate from the target distribution if we want to further increase this probability. But let’s return first to the story of Alice and Bob…
Mentored Decoding
Alice has decided to stop writing after her final masterpiece. She now focuses on mentoring Bob who aspires to be an author as well. Their way of working has remained the same with one major difference: Alice evaluates differently the sequence of candidate words suggested by Bob. In the past, Alice used to discard any word that she would not have written herself. She now wants Bob to find his own voice and only reject a word if it is clearly inadequate. For example, she can reject a spelling mistake, an awkward turn of phrase or a plot hole.
Compared to the previous situation, Alice interrupts Bob less frequently and their manuscript is progressing faster. The resulting book will not have the same style as Alice’s books but it will be of high quality thanks to her mentoring.
In a similar fashion, we are now ready to diverge from the target distribution in a controlled manner to increase the probability to accept draft tokens. More specifically, we want to find the values of \((r_i)_{i \in V}\) or \((s_i)_{i \in V}\) that maximally increase the probability to accept \(i\) while maintaining the Kullback-Leibler divergence between the resulting distribution and the target distribution under a certain constant \(D\).
Since we only focus on one token, we can simplify our notations:
- \(p_i = p(i\mid x_1...x_{n+k-1})\);
- \(q_i = q(i\mid x_1...x_{n+k-1})\);
- When dummy variables are not specified explicitly, e.g. in \((r_i)_i\), \(\sum_i\) and \(\forall i\), they correspond the whole vocabulary: \((r_i)_{i \in V}\), \(\sum_{i \in V}\) and \(\forall i \in V\).
The probability to obtain token \(i\) with the speculative approach is then \(\pi_i = p_ir_i + s_i (1 - \sum_j p_jr_j)\) (Chen et al., 2023) and \((r_i)_i\) or \((s_i)_i\) are the solutions of the following optimization problem:
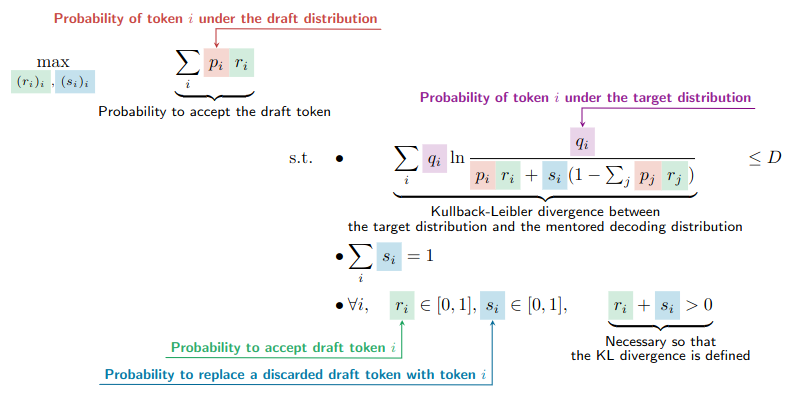
Solving the Optimization Problem
Fortunately, solving this non-linear optimization problem with close to \(10^5\) decision variables is feasible with limited computational overhead. In the attached proof which is mainly based on the Karush-Kuhn-Tucker conditions (Kuhn & Tucker, 2013), we show that:
- a unique solution exists in non-trivial cases;
- for this solution, \((r_i)_i\) or \((s_i)_i\) verify:
- \(r_i = \min(1, \frac{q_i}{\alpha p_i})\) for a certain \(\alpha\)
- \(s_i = \frac{1}{1-\sum_jp_jr_j}\max(0, \frac{q_i}{\beta}-p_i)\) for a certain \(\beta\)
- there is a one-to-one relationship between \(\alpha\) and \(\beta\) in non-trivial cases so choosing \(\alpha \in ]0, 1]\) is enough to find the solution of the optimization problem for a certain \(D\);
- the objective function and the Kullback-Leibler divergence in the first inequality constraint are decreasing functions of \(\alpha\).
These findings imply that computing the solution to the optimization problem is straightforward using a binary search on \(\alpha\). More precisely, the diagram below presents the mentored decoding algorithm:
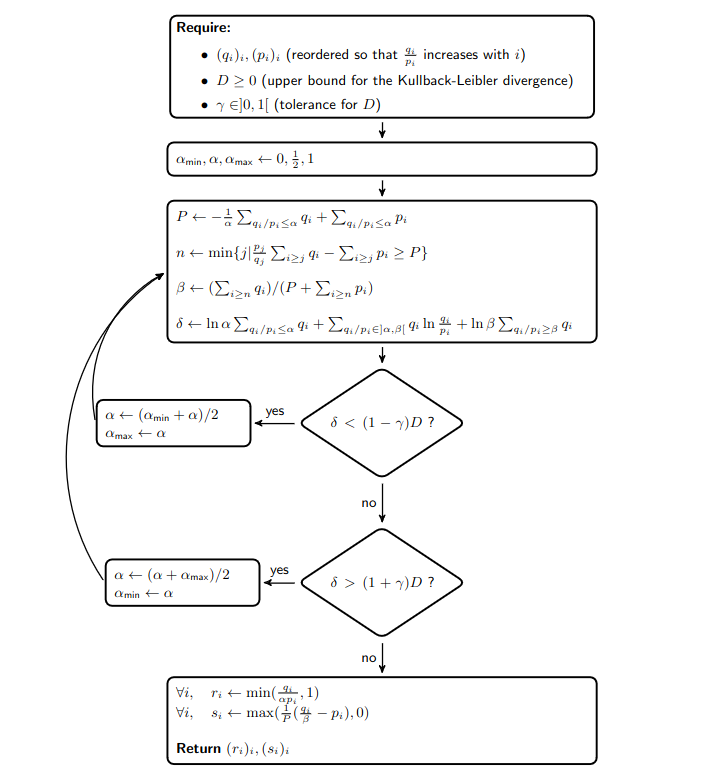
Furthermore, the following facts reduce the computational overhead of mentored decoding:
- Since we know that \(r_i \geq \min(1, \frac{q_i}{p_i})\), we can compute \(r_i\) and \((s_j)_j\) only when the value \(u \sim U([0, 1])\) drawn at random to accept or reject the draft token is greater than \(\min(1, \frac{q_i}{p_i})\);
- When the Kullback-Leibler divergence between the target distribution \((q_i)_i\) and the draft distribution \((p_i)_i\) for a given token is less than \(D\), we can directly accept the draft token;
- All the values for \((\sum_{i \leq j} q_i)_j\), \((\sum_{i \leq j} p_i)_j\), \((\sum_{i \geq j} q_i)_j\), \((\sum_{i \geq j} p_i)_j\), \((\sum_{i \leq j} q_i \ln\frac{q_i}{p_i})_j\) and \((\frac{p_j}{q_j} \sum_{i \geq j} q_i - \sum_{i \geq j} p_i)_j\) can be computed in a vectorized manner before the loop to save time.
First Experimental Results
As a first experiment (full code here), I tested mentored decoding on an English-to-French translation task with a subset of the WMT15 dataset and T5-large and T5-small as the target and draft models.
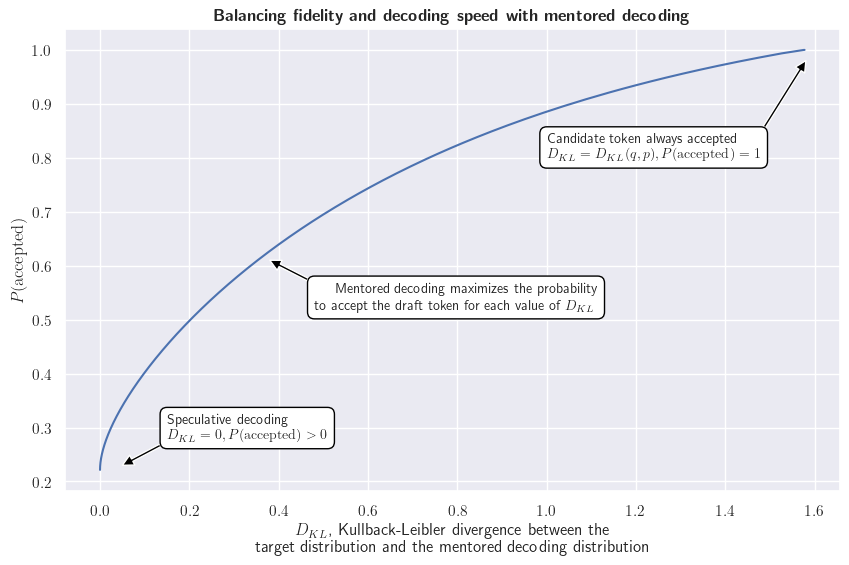
If we first look at a single token, we can visualize the solutions of our optimization problem for various values of the Kullback-Leibler divergence. The following chart illustrates the balance between the probability to accept the draft token (\(\sum_i p_ir_i\)) and the fidelity to the target distribution.
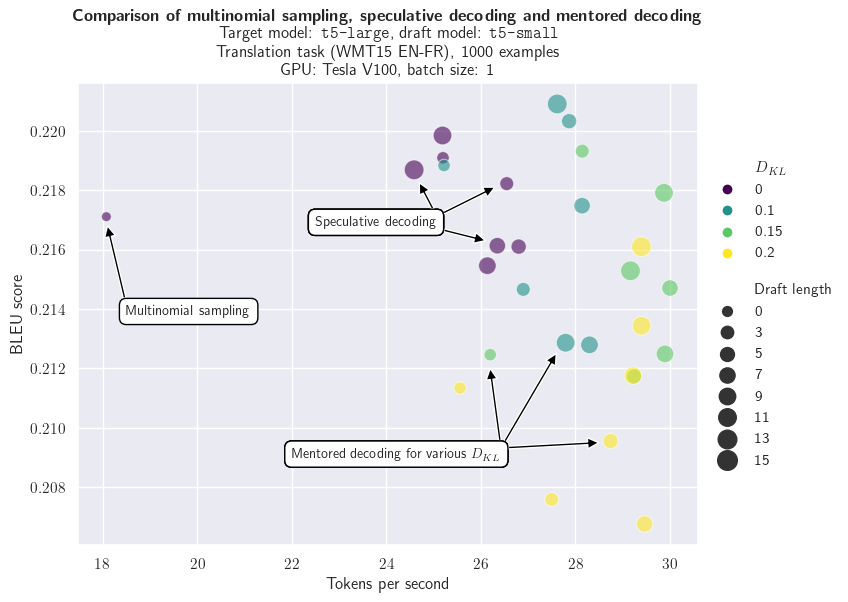
Evaluating mentored decoding requires measuring both the decoding speed and a performance metric for the downstream task, for example the BLEU score here. The latter is important: since we allow a deviation from the target distribution, we need to assess the potential impacts on the task of interest. The next chart compares multinomial sampling, speculative decoding and mentored decoding for various draft lengths and values of the Kullback-Leibler divergence (only for mentored decoding). We can see that:
- Speculative decoding significantly improves the decoding speed in comparison with multinomial sampling;
- Mentored decoding further increases the number of tokens generated per second;
- Compared with multinomial sampling, speculative decoding and mentored decoding with the smallest value of the Kullback-Leibler divergence do not appear to significantly differ in BLEU scores (which is expected for speculative decoding since the target distribution is preserved);
- Unsurprisingly, increasing the Kullback-Leibler divergence both accelerates the text generation and degrades the BLEU score.
Conclusion and Further Work
In this blog post, I introduced a lossy variant of speculative decoding. It maximizes the probability to accept draft tokens for a given bound on the Kullback-Leibler divergence between the target distribution and the resulting distribution. The initial experimental results above suggest that mentored decoding can increase the decoding rate, either moderately with limited impact on the performance of a downstream task or more strongly at the cost of a noticeable degration of this performance.
Extensive experiments are needed to explore the spectrum of tasks and models for which mentored decoding is relevant. In particular, it would be interesting to empirically test the following intuitions:
- Tasks for which valid answers can be written in various ways (e.g. translation, summarization or chain-of-thought question answering) would benefit more from mentored decoding than tasks with a narrow range of valid answers (e.g. speech-to-text);
- Mentored decoding would work better with a highly capable target model, capable not only to perform the downstream task but also to assess alternatively worded valid answers.
Many thanks to the authors of the articles mentioned below and to the maintainers of the various software libraries used for this work, in particular Transformers, PyTorch, TikZ and annotate-equations. Cover image created with ArtOut
References
- Leviathan, Y., Kalman, M., & Matias, Y. (2023). Fast Inference from Transformers via Speculative Decoding.
- Chen, C., Borgeaud, S., Irving, G., Lespiau, J.-B., Sifre, L., & Jumper, J. (2023). Accelerating Large Language Model Decoding with Speculative Sampling.
- Stern, M., Shazeer, N., & Uszkoreit, J. (2018). Blockwise Parallel Decoding for Deep Autoregressive Models.
- Joao Gante. (2023). Assisted Generation: a new direction toward low-latency text generation. Hugging Face Blog. https://doi.org/10.57967/hf/0638
- Kuhn, H. W., & Tucker, A. W. (2013). Nonlinear programming. In Traces and emergence of nonlinear programming (pp. 247–258). Springer.